TLDR
Vulpine is an experiment in compiling human-facing code into a representation that is cheaper and cleaner for models to reason over, then compiling it back. We mine repeated AST patterns from real GitHub code, 2,000 macros from ~76k FastAPI training files and swap matching snippets into macro form while everything else stays ordinary Python. On 13k held-out eval files, that translated to 13.8% fewer tokens (cl100k_base) and 99.8% structural roundtrip success after we expand macros back.
Link to github
Jump to benchmarks
Why compile code for LLMs?
Coding agents mostly operate on raw source code. Source code is optimized for humans: it is easier for us to read, write, reason about, review, and maintain. We can think of today's programming languages as an abstraction over machine code, an interface between humans and machines.
Those languages are optimized for people: syntax, macros, and built-ins are all designed with human readers in mind. But, LLMs are a different consumer of code. They do not need the exact same surface form that humans need. They need a representation that preserves program meaning while making the structure cheaper and cleaner to process.
With that mission, we set out to build Vulpine, the compiler. Compilers are usually unidirectional; there is little need, broadly speaking, to go from a low-level language back to a high-level one.
Traditional compilers mostly move in one direction:
human code → lower-level representation → machineVulpine needs to move in both directions:
human code → model-facing representation → LLM → human codeThat changes the design constraint. The compiled form cannot just be compressed. It has to be expandable back into useful source code. It has to preserve identifiers, control flow, types, literals, framework semantics, and the parts of the program that humans and agents both rely on.
The goal is to test whether a model-facing representation can reduce token cost while preserving enough structure to be useful in coding-agent workflows.
That is the experiment.
A hand-tuned example (Python)
We picked Python first, familiar to us, easy to experiment with, and widely used. Our first pass at the compiler was manual. The tokenizer we started with was cl100k_base.
We looked at structures that show up constantly in Python and asked how to make them cheaper in tokens:
for x in range(len(y)): # 7 tokensHere there are only two variables, x and y. We could represent the loop with a new macro:
for_macro(x, y) # 6 tokensThat already saves a token, but we can push further by changing how macros are written:
macro x y # 3 tokens | 50% reductionThat reduction was significant. We knew the direction; the hard part was scaling it across the whole language.
Mining repeated AST patterns
The first problem was finding which patterns repeat most often. That sounded simple: scan large codebases, find common shapes, done. It was not. We had to handle edge cases and multiple patterns that mean the same thing. Matching on ASTs instead of raw strings helped.
We ran an early pattern miner. Bluntly, the results were disappointing. Many extractions were too vague or too specific, for example, var1 var2 var3, which carries almost no structural signal. We had to tune the ratio of keywords to variables (we call the variables holes), plus minimum and maximum counts for keywords and holes, until the miner produced useful templates. That took a lot of experimentation.
One frequent pattern is the classic assignment chain:
# python
a = b = c = 0 # 8 tokens
# vulpine
macro a b c 0 # 5 tokens | 37% token reductionNaming and applying macros
Next we had to name the patterns. In practice, this meant naming the macros. The most token-efficient shape is macro_name var1 var2 ..., where the macro_name is preferably a single token. Any macro then costs roughly len(vars) + 1 tokens. We only kept patterns where that beat the original span.
Naming was its own puzzle. Existing Python builtins would clash with real code, while new English names could look like ordinary identifiers and change how the representation is read. The compiled form is not meant to be pleasant for humans to write. It is an internal representation between source code and the model.
So we went multilingual. A macro name can be a character or word from another script, as long as it stays cheap under the tokenizer. This gives us compact, unique symbols without colliding with normal Python. LLMs operate over tokens, so this syntax is easier for them to learn than it is for humans to type.
क var1 var2 var3At that point we had a pattern miner and a macro map produced by the miner.
Roundtrip and fallback
The compiler step became almost mechanical. For each snippet we parse Python to an AST, walk the tree, match mined templates, replace hits with macro form, and leave everything else as Python. We did not want to transform code where we were not confident, keeping the OG python as fallback When several macros matched, we picked the substitution with the greater token savings.
That worked well, we could turn raw Python into the compiled code reliably.
The reverse path was more straightforward in principle: run the expansion logic in reverse, a decompiler driven by the same template library. In practice it surfaced a lot of edge cases we iterated on in the compiler design.
Benchmark Run
Preparing Dataset
We built a dataset from public GitHub: the top 800 FastAPI-related repos (by stars) for pattern mining and the next 200 for evaluation. After filtering and per-repo caps, that yielded ~76k Python files in the mining DB (~760 repos) and another ~13k files across ~187 eval repos.
Mining Patterns
We then started with pattern mining. To do so correctly, we swept hyperparameters to maximize useful coverage while limiting noise and trivial matches:
| Parameter | Value(s) tested | Value used (final run) |
|---|---|---|
| Min keyword-to-hole ratio | 0.3–1.0 | 0.75 |
| Max keyword-to-hole ratio | 2.0 | 2.0 |
| Min structural length | 3–7 AST nodes | 4 AST nodes |
| Support threshold | 100–1000 | 500 |
| Max holes per pattern | 3–12 | 6 |
That run produced 2,000 mined patterns.
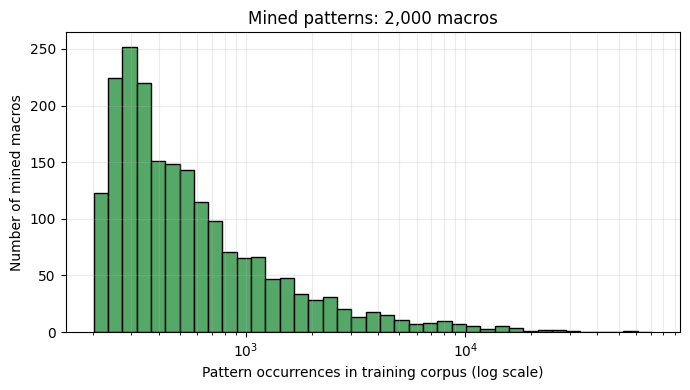
Compile and Roundtrip on the eval set
Each pattern received a macro name. We used single-token Unicode symbols (Arabic, mathematical alphanumeric symbols, and other rarely ambiguous scripts) so names stay unique and cheap under cl100k_base.
The mined macros translated eval Python into compiled format; unmatched regions stayed native Python. Of 13,286 evaluation files, 32 were dropped as invalid Python and 157 were passed through as originals when compression would not help.
We then reverse-compiled all 13,254 macro outputs back to Python.
Results
Token compression
We measured 13,254 files that compiled successfully (after dropping 32 invalid inputs). On corpus totals (18,984,865 input tokens), compiled format used 16,373,332 tokens (−2,611,533; −13.76% vs input). A revert guard writes the original back when macro output would use more tokens, so zero eval files ended larger than their source.
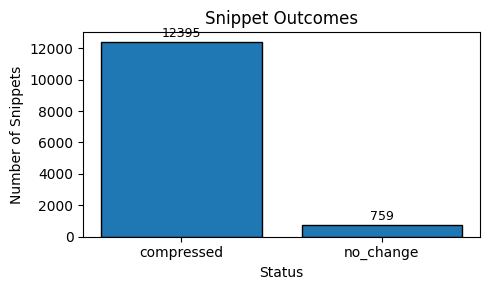
Roughly 94% of files saw some compression; about 17% saved more than 20% of tokens on that file. Weighted net reduction across all input tokens (bootstrap 95% CI on a subset with top outliers dropped): ~13.8% (CI 13.6–14.0%).
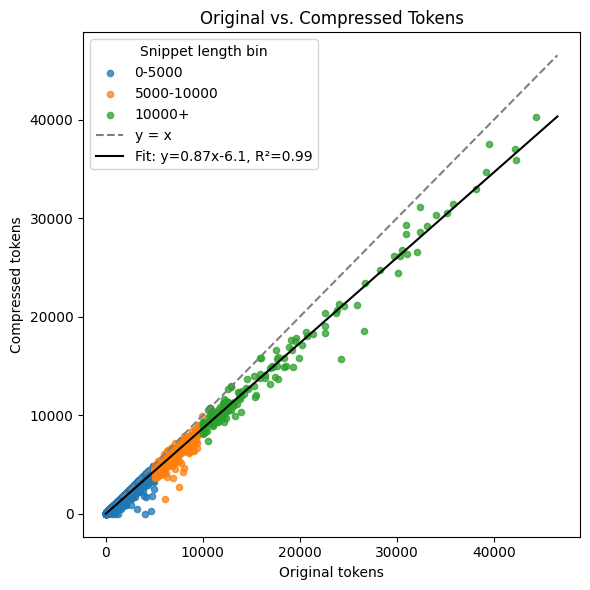
Points below the diagonal are winners; the fitted line shows how compression scales with file size. Length bins: 0–5000, 5000–10000, 10000+ tokens.
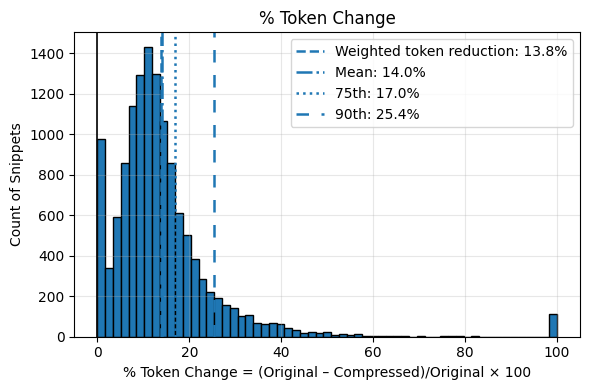
Distribution of (input − compiled) / input × 100, with vertical markers for weighted net, median, mean, 75th, and 90th percentiles.
Roundtrip fidelity
Structural checks compare comment-stripped input to roundtrip Python. This is AST equivalence, not byte-for-byte equality, formatting and comments can differ even when status is ok.
| Status | Files | Share |
|---|---|---|
| ok | 13,230 | 99.82% |
| mismatch | 13 | 0.10% |
| parse_error | 11 | 0.08% |
| Total compared | 13,254 | 100% |
Failures cluster around f-strings, triple-quoted strings broken during expansion, and Unicode punctuation inside literals. This is not random drift.
Where this leaves us
Vulpine is a bet that a lot of code in the wild is repetitive structure, not unique syntax and that an LLM-facing layer can exploit that without breaking the human-facing layer. On 13k FastAPI eval files we see a real ~14% token win and ~99.8% AST roundtrip success, with failures clustered in a few hard cases we think we can chip away at.
That is encouraging for agent context windows and cost, but it is not magic: coverage is partial, macros are mined not hand-designed, and we still have work beyond this corpus. Next we want tests that ask whether models actually use the format better not just whether we can roundtrip it.
If you are experimenting with coding agents, we would love your take on this.